Generative AI (GenAI for short) is a subset of machine learning. GenAI’s models can learn and uncover complicated patterns in massive datasets. These datasets can be images, numeric data sets, audio data, sensor data and much more!
Large Language Models, or LLMs, are an important part of GenAI resolution, and they are the primary cause of the recent surge of interest in this area of artificial intelligence. LLMs have been trained on enormously large text datasets, from all over the internet, over a long period of time – which in turn employs a large need for computational power.
LLMs proved their capacity to comprehend material, deconstruct complicated tasks, and solve problems using reasoning. All of this is due to the massive size of these models, which can have billions (and sometimes trillions) of trainable and highly customised parameters.
There are different types of LLMs, despite the fact that they are all based on the same research paper, “Attention is all you need” (2017). The original model consisted of a connected set of encoders and decoders, and it included a novel mechanism called attention (as suggested in the paper’s title). The objective of the paper was to solve a translation task, or in other words, sequence-to-sequence tasks.
Now while the original architecture uses both the encoder and decoder component, there are other variations which we will explore now:
Encoder-Only Models
Encoder-only models use only the first part of the Transformers model (as is obvious from the name). They’re also referred to as Auto-encoding models.
The way these models are trained is by using a technique called mask language modelling. In this technique, a random token from the input sequence is replaced by new special token called < MASK >, and the objective of the Encoder-only LLM is to predict the masked word. They call this process the denoising process.
For instance:
These models build bidirectional representations of the input sequence, which means they look at the tokens before and after the masked token, in order to predict.
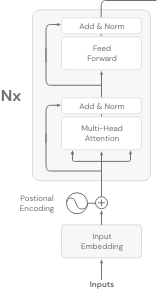
Encoder-Only models are a good choice, when the task requires full understanding of the input sentence. For instance:
• Sentiment analysis
• Entity recognition
• Word classification
Examples of encoder-only models:
• BERT
• ROBERTA
Decoder-Only Models:
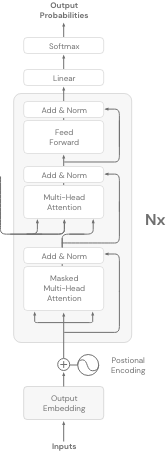
Decoder-models use only the decoder part of the transformer architecture. They are also known as autoregressive models.
The objective of these models is to predict the next token, given the previous tokens. In contrast to the Encoder-only models, these models build unidirectional representations of the input sentence.
For instance, this table shows how these models work. The green cells represent the input, the yellow cells represent the token to predict, and the red cells represent the tokens to ignore.
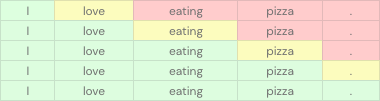
Decoder-Only models are good at predicting the next word. However, these models proved their abilities on other tasks (classification, recognition, etc) using zero-shot and few-shot learning.
Example of Decoder-Only models:
• GPT family
• BLOOM
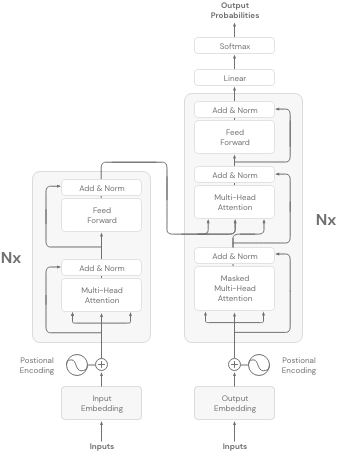
Encoder-Decoder Models:
The Encoder-Decoder models, or in other words, seq-to-seq models, use both the encoder and decoder part of the transformer architecture. The objective for these models varies and depends on each model.
Popular use cases of using encoder-decoder models are:
· Translation
· Summarisation
· Answering direct questions
Here’s some popular examples of encoder-decoder models:
• T5
• BART
To conclude
There are different types of transformer architectures used across multiple industries, each useful when performing specific tasks. Each one of them is specialised in one or more domains, therefore, when choosing which model to choose, you must choose the one that suits your application and specific use cases.
Luckily, our teams at Firemind have a very strong understanding of utilising the right Encoder and Decoder models for your use case. With pre-built in-house accelerators such as PULSE that can rapidly accelerate your generative AI pipeline, we’re your go-to partner for taking the leap into a GenAI workload.
To find out more, speak with our team here.


